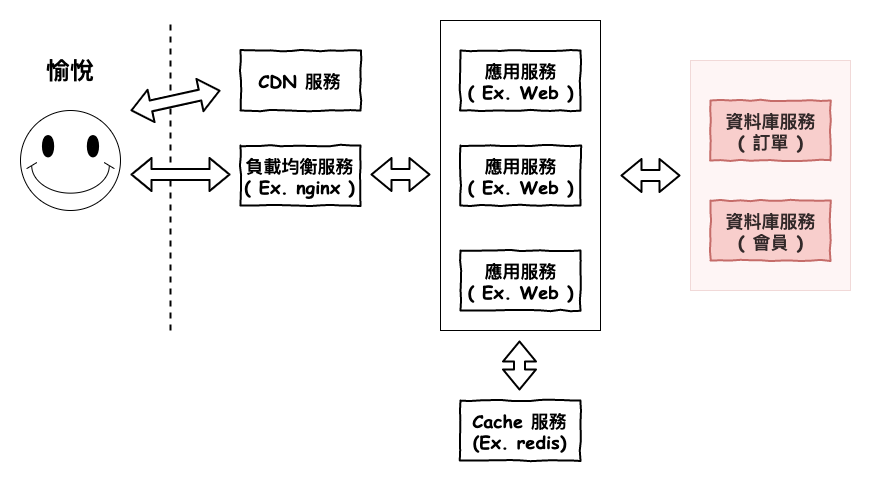
上一篇文章中,咱們介紹了資料庫層的分散的第一個起手式『 讀寫分離 』,這個方案是將寫與讀分散在不同的機器上,正常情況下,大部份的系統使用這種方案就已經可以處理很好了。
但 !
如果你已經將資料庫層與緩存層的架構都已經建立好,但還是發現有性能貧頸,那接下來才會建議使用幾個方案,因為這些方案沒用好,會衍生出非常多的問題。
本篇文章分為以下幾個章節,這些就是接下來咱們要來學的擴展法。
要使用以下的擴展方法時,先確認你的資料庫是否以下的問題是否有發生。
有以上事情發生才開始往接下來的擴展走。
沒事真的別用它們
它可以解決
問題 1 : 單庫太大,導致硬碟空間不夠囉
與
問題 2 : 單庫寫入量太大,導致每一次新增或更新性能非常的吃緊
首先第一個要介紹的就是分庫,它的基本定義如下 :
將一個大大的資料庫,依據『 規則 』拆分成小的資料庫
其中上述說的規則,在傳統上可以分為以下幾種 :
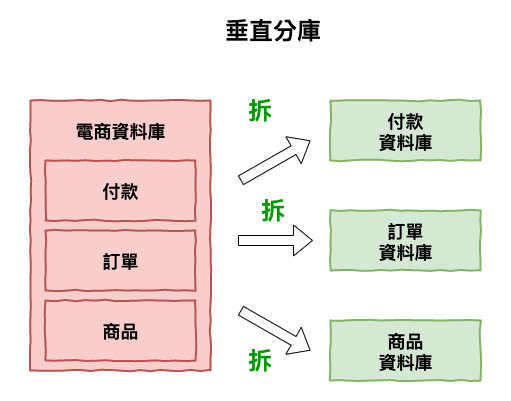
圖 1 : 垂直切分範例
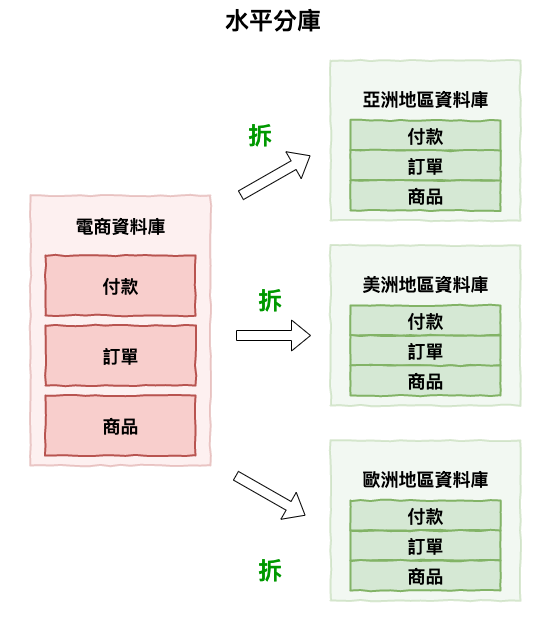
圖 2 : 水平切分範例
這個方案基本上在業界應該算是非常常見的方案,尤其是以業務的垂直切分這個方案,整體而言還是有不少的優點,如下幾個 :
業界的確很常使用這個方案,它們會根據業務需求來分成多個庫,可是上面不是建議沒必要,不要這樣搞嗎 ? 嗯對沒錯,但是如果是下面這種情況下,那的確可以切分 :
假設在業務擴展初出,所有資料都寫到同一個資料庫中,但後其長大後,就將不同『 單位業務 』的資料分不同資料庫,它們彼此間很獨立,非常少會一起使用
這種情況下,我覺得切分合理,而且這很常見。就算是咱們某個資料庫中還是有一堆奇奇怪怪不知道是幹啥的表,或是其它業務的表,這些都是一間公司從 0 至 1+ 時都會有的過程。
但如果是一堆需要共要在一起的業務,硬是要把他切分成不同資料庫,那我想打爆那個提出這樣切的人的頭。
這種方法可以解決以下的問題 :
它可以解決問題 3 : 單表資料量太太,導致每一次操作時都非常的慢。
簡單它們的概念都 :
將一張很大的表,根據『 key 』來分成小張的表
它本質上是應用層自已手動實現,根據規則將一個表,分成多個表,這表可能在同一台機器上,或是不同機器上,應用層 sql 代碼需修改。
分表這種擴展法是用在單表太大的情境。
假設你們的系統是聊天室這種類型的系統,然後你們會將用戶說的每一句話儲存在某一張表,那你們遲早會碰到表太大,影響查詢這種問題的。
不過先說一下,並不是一定要用這種方法來處理此情境,像以咱們公司是這樣處理的。
如果真的有需要去 s3 找資料,你也可以用 aws athena 去查詢資料的,雖然有點貴,但是久久才用一次,沒毛病。
上述是題外話,假設咱們真的都需要儲放在資料表中,那咱們就只能選擇『 分表與分區表 』這個方案囉。
不過說句真心話,沒必要真的不要用它,因此之後會很多問題。
拉回分表
分表的基本概念就是如下,咱們假設以 id 為 key,將這張表拆成如下圖 3 所示。分區表下篇文章會說明。
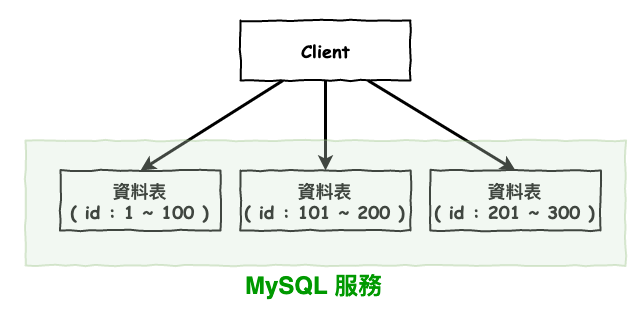
圖 3 : 分表範例
問個問題,分表有需要分到不同的機器嗎 ? 例如下圖 4 所示呢 ?
除非,你的單表真的大到,就算進行分表後,單機仍然無法負荷它的資料量,那這樣才可以考慮,不然雷會很多,因為這就代表分庫 + 分表的問題你都需要一同考慮。
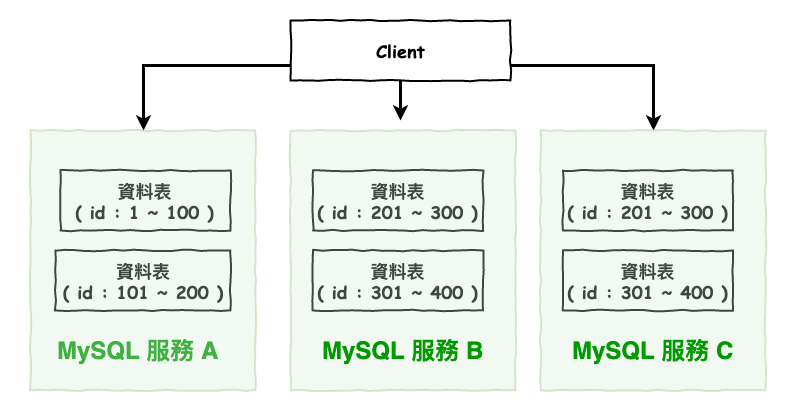
圖 4 : 分表不同機器圖
分片( Sharding )就是咱們要用什麼規則來去分割資料的意思。以我們這裡來看就是咱們要用什麼欄位,來去分割資料。
先說一下,我們會很難到完美的分片,一個完美的分片可以讓我們做到以下的事情 :
咱們很難找到一個完美的選擇,但是可以先定一個最低的標準選項 :
高基數欄位,這是最低標準
為啥 ? 因為這樣才好分割,你想想如果選擇性別男與女來當分割,那這樣你不是只能分成兩份嗎 ? 如果又滿了,你要如何處理 ?
然後這裡列一下一些常見的分片欄位選項 :
『 自動產生編號 』 或是 『 日期 』
根據 id 或日期來分區的這種都算是升序特性欄位。以 id 為例,它們的分割方式為 :
id_1_1000 : 儲放 id 編號 1 至 1000 的資料
id_1001_2000 : 儲放 id 編號 1001 至 2000 的資料
但是這事實上不能說是好選項,主要的原因在於 :
操作會壓在一張表上
因為通常新的資料者是會放在同一張表,所以大部份的操作都會壓往他身上。
根據 id + hash 來進行切分,假設咱們有個 hash 函數如下 :
hashId = id % 10
這種做法比上述的直接編號來分割還優質點,因為它可以平均的分散到不同的表上。先說一下上述只是 hash 的簡單範例,實際上不一定是用上述方式分割。
像是一些沒有規則的欄位,例如信箱或是一些亂數編號這種,這種欄位分片可以平均的分散到每一張表,但是比較大的問題在於 :
查詢
由於分配是隨機的,所以查詢時不知道要去那張表找,所以只能一個一個慢慢找。
假設咱們有個資料表是專門存放聊天訊息的,有以下欄位 :
id, type , text, user_id, created_at
type : 它有 5 種類型 ( 可能是表示不同的服務 )
那這時如果我們只選擇 type,會發現它的基數太小,怎麼分就可能只有五張表,這樣還是會碰到貧頸的。
但這時咱們可以轉個想,如果一次用兩個欄位呢 ?
{ type, created_at }
例如咱們可以根據 type 與 created_at 來當分片欄位組合,這樣的話資料表會分為如下圖 5 所示。
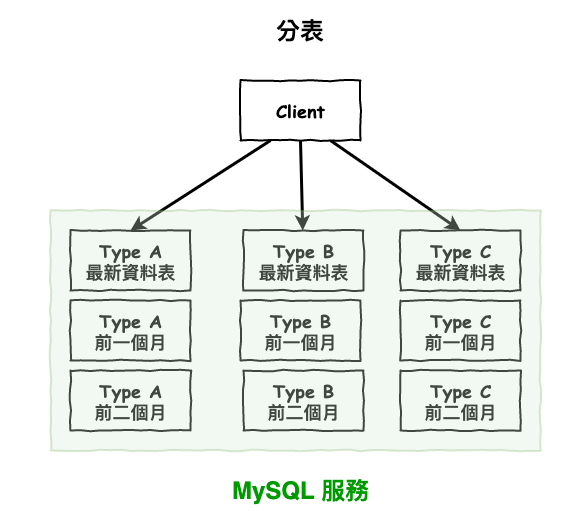
圖 5 : 組合型範例
這樣就有幾種好處 :
上面這個只是組合型的範例,不代表一定要這樣使用,這裡只是要點醒一下 :
分片欄位不一定是要一個欄位組成
咱們之前的這兩篇文章中,有談到單機一致性的問題。
30-15 之資料庫層的難題 - 單機『 故障 』一致性難題
30-16 之資料庫層的難題 - 單機『 並行 』一致性難題 ( 1 )
30-17 之資料庫層的難題 - 單機『 並行 』一致性難題 ( 2 )
而它們都是依賴 mysql 所提供的 redo log 與 undo log 還有鎖之類的功能,來達成事務的 acid 特性。
那如果這個換成『 多台 』資料庫的話,你要如何處理呢 ?
這個問題咱們會在之後的文章『 分散式事務 』的主是中來慢慢的談談。
在分庫以後,基本上有以下幾種方法解決 :
這裡是比較建議分庫後儘量不要用 join,因為坑會有點大,而且你儘然分庫了,你還很常需要 join,那是不是要想想,分庫的規則有問題了呢 ?
通常咱們在分表以後,都需要自已去指定要去那一張表來處理,但是這樣非常的麻煩,所以我們通常會使用 mysql 中間件來處理,變成如下圖 6 所示,這之後會開一篇文章來介紹中間件。
正常分表後,SQL 指定修改
SELECT * FROM table_2019_01
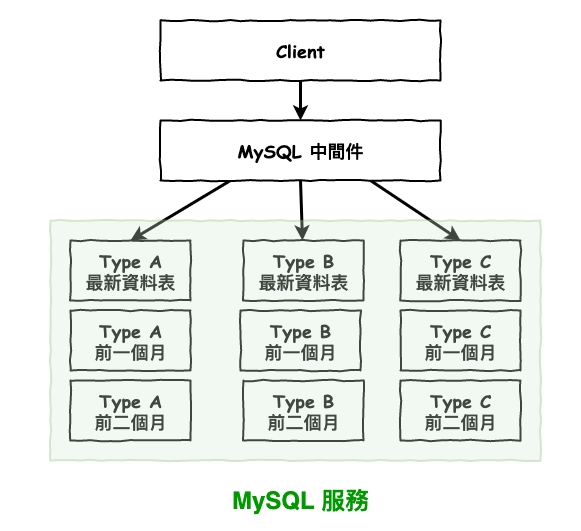
圖 6 : 中間件。
在分表或水平分庫以後,你可能還要考慮每一張表的唯一編號要如何產生,正常只有一張表時,咱們可以使用自動產生編號來建立順序的編號,但多張時就不能這樣用,因為會衝突。
基本上有以下幾種方案 :
方案 1 : UUID
簡單,但是缺點在於沒順序、空間大,這兩個都會影響性能。
在順序的編號,在查詢時可能增加不少效率。而 uuid 所佔空間比較大,會影響到所建立的 b+ 樹每個索引節點的大小,進而影響到操作性能。
方案 2 : 自動編號 + 偏移
假設你有 4 張表,那他們的生成編號為 :
A 表 : 1,5,9,13
B 表 : 2,6,10,14
C 表 : 3,7,11,15
D 表 : 4,8,12,16
但缺點就在於不好擴展。
方案 3 : redis 生成
redis 有提供一個方法 :
incr
可以使用它來產生全局的順序編號,但缺點就在於需要連 redis 處理,還要考慮它是否活這。
像咱們在單一表進行分頁時,通常是會下如下的指令,說要拿第 6 至 15 的資料 :
SELECT * FROM table ORDER BY time LIMIT 5,10;
但是現在一個大表變成如下 :
table = tableA + tableB + tableC
在分表的情境中,要如何處理呢 ?
首先假設如果咱們的分表是使用『 區間 』來拆分例如日期,那這種情況下,應該還是到指定的表去尋找就夠了,沒啥毛病。
但如果是用 hash id 這種來分的表呢 ?
有人會想說,那就每個表的資料都抓出來,在排序然後再抓取前 n 個值不就好呢 ? 服務會炸裂的,分表的原因就是單表太大,你還要進行排序 ( nlogn ) ?
說實話,我到還沒碰到分表然後又要分頁的情況,這時只能給點參考文件,目前我覺得寫的最完整的是這一篇文章,這個作者也是我之前有提過的『 架構師之路 』這一系列優質文的筆者,他的文章真的只能說優質上等來評價。
而至於分表分頁這問題,等未來我在這個問題有更深入的理解後,在開篇文章來談談。
本篇文章中,咱們討論了另外兩種資料庫層的擴展 :
基本上我覺得這兩種都是沒必要,不要用的東西,因為如果你在還沒到性能貧頸時就用這幾招,你會面臨到的問題是一個大大的坑,請注意。
分庫這種場境,可以解決以下幾個問題 :
而分表方面可以解決以下幾個問題 :
雖然可以解決,但是同時也會帶來以下這些鬼問題,請注意。
這些問題 :
都是在分庫或分表『 前 』你就要思考好
分了後,才思考,你一定死。

